Informatikai pillér
7. pillér
Az egészségügy hatékonyságához, az egyes alkalmazott protokollok, beavatkozások, illetve újonnan bevezetendő módszerek eredményességének meghatározásához elengedhetetlen az ellátás során keletkező óriási adatmennyiség elemzése, illetve annak ezt megelőzően feldolgozható formába történő átalakítása. A Transzlációs Idegtudományi Nemzeti Laboratórium alapvető célkitűzése az adatvezérelt egészségügyi rendszer megteremtése az idegrendszeri eredetű betegségek kezelése és kutatása során, amelyhez elengedhetetlen az adatrögzítési módszerek fejlesztése.
A TINL koncepciójához illeszkedő informatikai megoldás tervezése és fejlesztése a következő lépéseket foglalja magában:
• adatgyűjtő rendszer tervezése (űrlapok specifikálása)
• az adatok nemzetközi standard szerinti megfeleltetése
• adatgyűjtésre alkalmas megoldások fejlesztése (e-Medsolution rendszerben, egyedi űrlaprendszerben)
• elemzésre alkalmas önálló TINL adatstruktúra, adatbázisok kialakítása (saját, PTE infrastruktúrán)
• adatok központi adatbázisba történő betöltésének tervezése és fejlesztése (saját, PTE infrastruktúrán)
• elemzések kiszolgálása
A projekt céljának teljesítése érdekében a következő informatikai fejlesztések valósulnak meg:
1. A betegellátás során jellemző adatok strukturált gyűjtésének kialakítása az e-Medsolution rendszerben, az erre alkalmas szakma-specifikus űrlapok fejlesztése és paraméterezése (a szakmai pillérek által elkészített specifikációk alapján);
2. Egyes betegségterületeken (mozgászavar és a gerincsebészet) a beteg által rögzített adatok gyűjtését támogató megoldás (Patient Reported Outcome) kialakítása, az erre a célra alkalmas Limesurvey rendszer paraméterezése és használatba vétele;
3. A különböző forrásokból származó adatok integrációját és elemzését biztosító központi adatplatform tervezése és fejlesztése, valamint az adatok transzformációját és az adatbiztonsági elvárásoknak történő megfelelését biztosító eljárások kialakítása.
4. A kutatások és elemzések kiszolgálása.
5. Az adatok védelmét biztosító megoldások és technológiák használata.
1. Strukturált adatgyűjtést biztosító űrlapok kialakítása az e-Medsolution rendszerben
Jelenleg a magyarországi beteginformatikai rendszerek által létrehozott adatbázisok nagyrészt szabadszöveges rendszerűek, nem kellően strukturáltak, emiatt digitálisan nem feldolgozhatók. A betegellátás (protokollok, intervenciók, stb.) javításához, illetve egészséggazdasági elemzések készítéséhez kettőzött munkával regisztereket kell képezni, csak így jönnek létre strukturált adatbázisok.
Az „igazi” strukturált beteginformatikai adatok (EHRs), beleértve a mért értékeket (például a laboratóriumi, képalkotó eredményeket, valamint a szövettani és biomarker teszteket) részletes adatokat tartalmaznak a betegek jellemzőiről, a terápiaváltás vagy megszakítás okairól, a betegség stádiumáról, valamint a mellékhatásokról. Ezek az információk kulcsfontosságúak az összehasonlító hatékonysági értékelés és kutatás szempontjából. A strukturált EHRs adatok a valós klinikai gyakorlatot tükrözik, bizonyítékot szolgáltatva, hogy az egészségügyi technológiák hogyan teljesítenek a tényleges populációkban, ami jelentősen eltérhet a regisztereken alapuló klinikai vizsgálatokban tapasztalt eredményektől. Ennek nemzetgazdasági szempontból is nagy jelentősége van, hiszen a strukturált adatok elemzéséből kinyerhető információk révén az egyes kezelések való világbeli hatékonyságára is fény derülhet.
A 7. pillér keretében végzett munkánk a strukturált adatgyűjtésre alkalmas egészségügyi informatikai háttér megvalósítására irányul. Az első fázisban a népegészségügyileg legfontosabb neurológiai betegségek strukturált űrlapjainak elkészítése és az űrlap készítés technikájának kidolgozása valósult meg. Számos betegség ellátásához (stroke, vérzéses stroke, mozgászavar, pszichózis, epilepszia, gerincsebészet, koponyasérülések, szklerózis multiplex, myasthenia gravis) specifikus, a nemzetközi és a hazai orvosszakmai irányelvekkel és protokollokkal összhangban álló, egyben a nemzetközi adatszabvány követelményeket magas arányban teljesítő űrlapokat hoztunk létre. Ez beépült a betegellátást támogató eMedsolution rendszerbe, és jelenleg több betegség kapcsán már „éles klinikai gyakorlatban” strukturált adatgyűjtéssel történik a PTE Klinikai Központban az ellátás, ami lehetőséget biztosít arra, hogy a gyűjtött adatokat klinikai, egészséggazdasági kutatások során használjuk.
Az ábrán – példaként – a stroke területen fejlesztett űrlapstruktúra felső szintje látható, több száz mező és rögzített változó használatával.

A TINL keretein belül kidolgozott űrlapokat a PTE mellett már több partnerünk is használatba vette a betegellátás során, ami jó alapot teremt a kutatásokban és elemzésekben történő szoros együttműködések megvalósításához. Reményeink szerint az egészségügy egyéb területei számára is irányadó lehet a betegellátási adatok általunk kidolgozott gyűjtési rendszere.
Egy párhuzamos fejlesztési fázisban az űrlapkitöltés teljességének és minőségének ellenőrzésére alkalmas, valamint az űrlapok használatának javítását szolgáló megoldások kialakítását kezdeményeztük az Egészséginformatikai Szolgáltató és Fejlesztési Központtal (ESZFK) történő együttműködés keretében. Ezzel a fejlesztéssel, funkcióbővítéssel kiegészítve az e-Medsolution rendszerben hosszú távon alkalmazható megoldás képes a strukturált űrlapok paraméterezésére, a betegellátás során történő töltésére és az űrlapkitöltések teljességének ellenőrzésére.
2. Beteg által kitöltött kérdőívek
Több betegségterületen jellemző igény, hogy a betegellátási folyamat általános protokolljához tartozóan a beteg személyes kérdőív kitöltéssel válaszol előre meghatározott kérdésekre. Ennek érdekében a TINL projektben – első körben – a mozgászavar és a gerincsebészet területén kerültek kialakításra a betegek aktuális állapotának – saját érzetük alapján történő – felmérésére alkalmas strukturált (nem szabad szöveges) válaszokat igénylő, a beteg állapotának felmérését célzó kérdőívek. A kérdőívek kialakítása a Limesurvey rendszerben valósult meg.
A kérdőívek kitöltése történhet az orvossal történő találkozás alkalmával (amikor a beteg tablet használatával válaszol a kérdésekre) vagy email értesítés alapján otthoni környezetben történő rögzítéssel. A két módszer esetén a kérdőívek tartalma megegyezik. A kérdőívek betegellátás során történő éles használata révén százas nagyságrendben állnak rendelkezésre a saját állapot megítélésével kapcsolatos adatok. Ezeket a további feldolgozás során eredmény (lelet) adatokként értelmezzük.
A válaszokhoz rendelt pontozási rendszer összesített eredménye alapján következtetések vonhatók le a beteg állapotára vonatkozóan.
3. Központi adatplatform tervezése és fejlesztése
A rendszer a forrásrendszerekből érkező adatot több fázisban, több rétegen keresztül dolgozza fel, míg végül elemzésre is elérhető és alkalmas lesz a felhasználók számára. Ezt sematikusan a következő ábra szemlélteti.
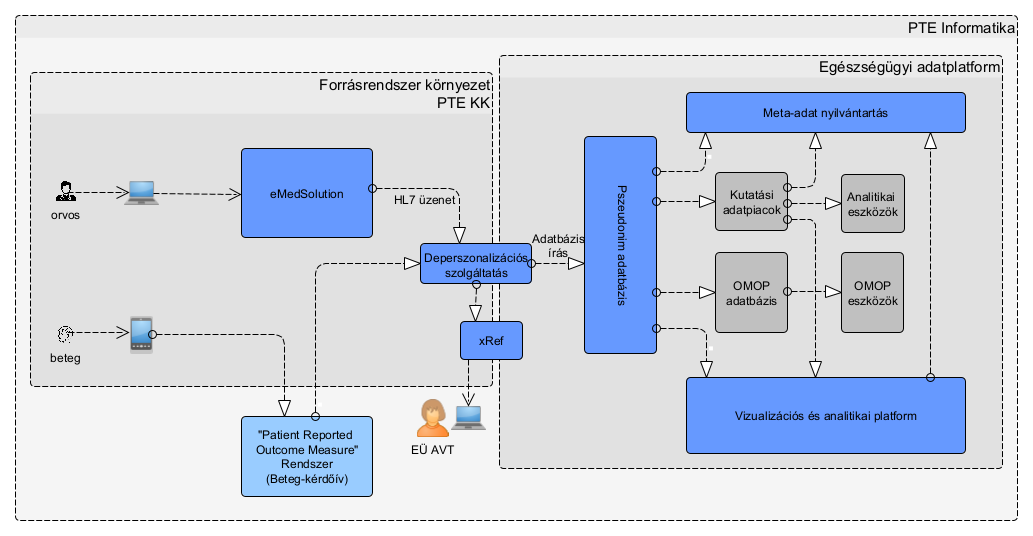
Az e-Medsolution rendszerből a betegellátási adatok az egészségügyi területen szabványos HL7 formátumban kerülnek kinyerésre, a Limesurvey rendszer (beteg által töltött kérdőívek adatai) egy kérdőív lezárását követően állítja elő az exportfájlt.
Az első feldolgozási fázist a forrásrendszer környezetében futó deperszonalizációs szolgáltatás végzi. Ennek célja, hogy a nyers bemenő adaton olyan transzformációkat végezzen, melyek eredményeképpen a forrásrendszer környezetét már álnevesített adat hagyja el. Az álnevesített azonosítók feloldótáblája (az eredeti és az elkódolt azonosítók párban) tárolása az elemzésre használt adatbázistól fizikailag is elkülönített rendszerben történik (xRef adatbázis).
A rendszer adatbázisába beérkező (álnevesített) adat a staging rétegben átmenetileg kerül tárolásra, várakozva a rendszeres áttöltésre, mellyel a teljes adatkört tartalmazó adatbázisba (dwh) érkezik.
A központi adatbázis (dwh) struktúráját a következő ábra szemlélteti. Az entitás diagram alapján jól látható, hogy a központi adatbázisban, adatplatformon a betegellátás logikáját és a komplexebb kutatásokat, elemzéseket is támogató struktúrában állnak rendelkezésre az adatok, kiemelten a betegek általános adatai, az orvos-beteg találkozások adatai, a diagnózis adatok, a járó- és fekvőbeteg ellátás és beavatkozás adatai, valamint leletezések jellemzői.
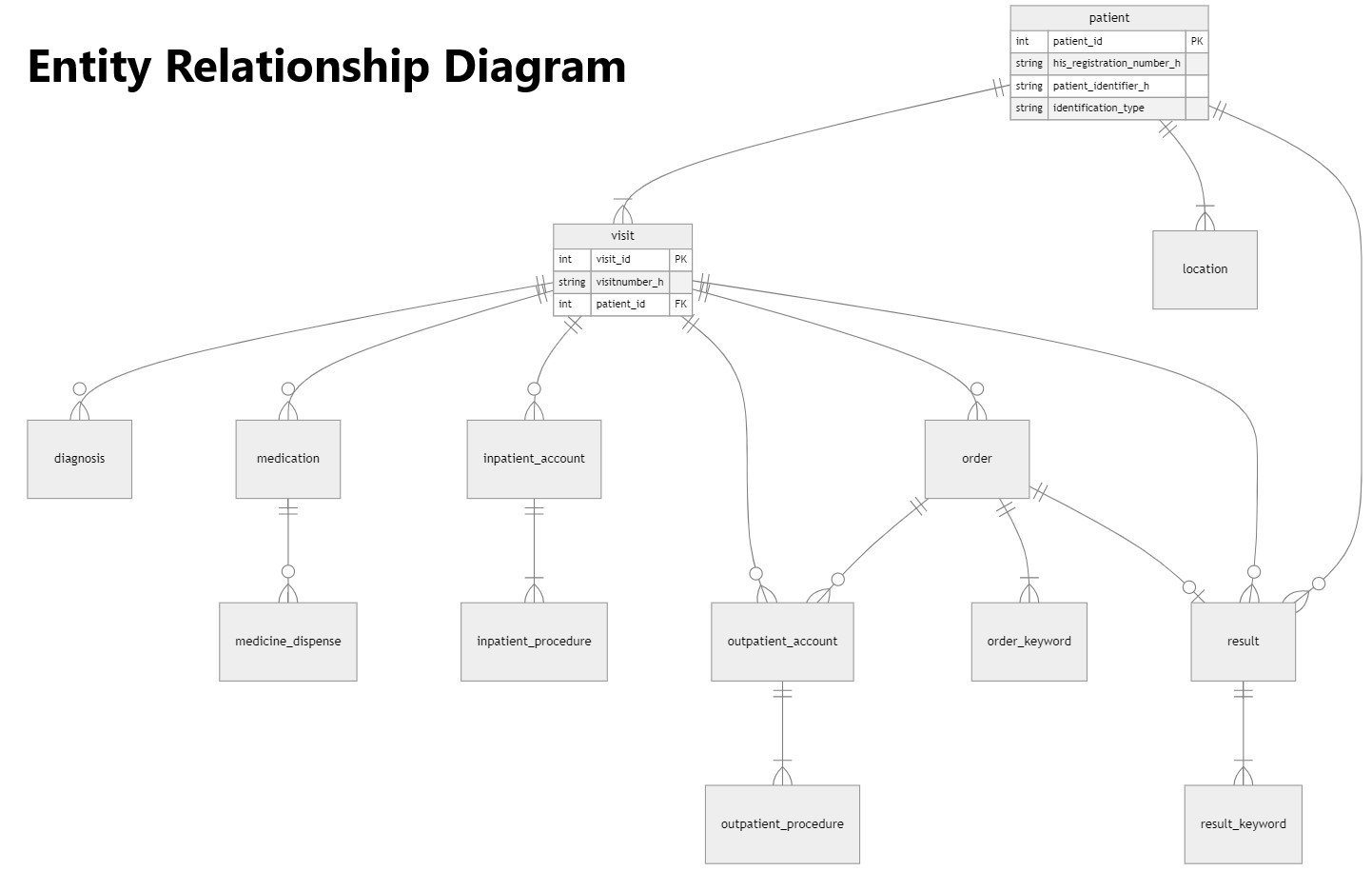
A központi adatbázisba a 2014-2024 közötti e-Medsolution rendszerben rendelkezésre álló, a TINL projekt TUKEB engedélye szerinti betegellátási adatok kerülnek betöltésre, továbbá a közeli jövőben az adatplatform részei lesznek a beteg által töltött kérdőívek adatai, valamint a stroke és mozgászavar betegségterület korábbi adatbázisokban kezelt adatai.
4. A kutatások és elemzések kiszolgálása
A kutatások specifikus céljaira kialakítandó, szűkített adatkört tartalmazó adatpiacok, valamint a nemzetközi egészségügyi adatszabványoknak megfelelő OMOP adatbázis a dwh rétegből épül fel időszakosan ismétlődően (jellemzően az OMOP réteg) vagy a kutatás igényeinek megfelelően (jellemzően az adatpiacok).
Az OMOP szerinti adatbázis réteg jellemzője, hogy azokat a betegellátási adatokat tartalmazza, amelyeknek van OMOP szerinti megfeleltetése, illetve az adatok álnevesített formában érhetők el ebben a rétegben. A 2014-ben alapított Observational Health Data Sciences and Informatics (OHDSI) kezdeményezés által létrehozott adatstruktúrát és adatszótárt 74 ország több mint 2000 csatlakozott intézménye használja egységes egészségügyi adatbázisként. Jelenleg a résztvevő partnerek összesen több mint 800 millió páciens egészségügyi adatát tárolják ebben a struktúrában.
Az adatpiacok alapvető jellemzője, hogy etikai engedéllyel rendelkező kutatáshoz kapcsolódóan egyrészt az adott kutatás szempontjából releváns beválogatási kritériumoknak megfelelő betegadatokat, másrészt szintén megadott paraméterek alapján meghatározott kontroll csoport betegellátási adatait tartalmazzák.
Az adatok kutatási célú hozzáférését biztosító eszközök között szerepelnek az OMOP adatbázisra fejlesztett speciális szoftverek (pl. Atlas), áttekintő, deskriptív elemzésre alkalmas vizualizációs eszköz (Apache Superset) és adatelemző programok, eljárás-gyűjtemények futtatására alkalmas fejlesztői környezetek (RStudio, JupyterLab). Az adatok katalogizálását és az adatok szakmai értelmezését segítő megoldásként az OpenMetadata rendszert alkalmazzuk.
A kutatók a rendszer végfelhasználóiként a számukra biztosított eszközök webes felületét érik el egy erre a célra létrehozott VPN hálózatba belépve.
5. Az adatok védelmét biztosító megoldások
Az egészségügyi adatok védelmét a következő technológiai megoldások biztosítják:
• A személyazonosítókat tartalmazó HL7 fájlokhoz nincs emberi hozzáférés (automatizált).
• Az adatfeldolgozás, az adattranszformáció izolált környezetben működik, VPN hozzáférés szükséges.
• A rendszerben kialakított adatkommunikációs csatornák minden esetben titkosított csatornán működnek, valamint rendszer- és adat-hozzáférési szabályok korlátozzák az adatok elérhetőségét.
• Az adatplatformon álnevesített (pszeudonim) adatok vannak.
• A HL7 fájlok feldolgozása is naplózott, csak hiba esetén tartalmaz adatokat a feldolgozott üzenetből.
• A feldolgozott HL7 fájlok törlésre kerülnek.
• Az álnevesített adatok újraazonosítására fordítótábla szolgál, amelyhez korlátozott a hozzáférés.
• A kutatók, elemzők csak a központi adatplatformon, annak különböző rétegeiben tárolt adatokhoz férhetnek hozzá, jogosultsági rendszer alapján.
